
Qdrant - 原来向量搜索并没有那么神秘
先看看对于向量和向量搜索的概念表述:向量本身是一个数学概念,表示一个量既有大小,又有方向。在AI领域,向量搜索指的是一种利用机器学习技术将非结构化数据(如文本、图片、视频等)转换为多维向量(即嵌入表示),并通过计算这些向量之间的相似度来检索信息的技术。
然后结合实际项目,按照我粗浅的理解,大致可以认为原本存入数据库中的就是一段文字、一张图片、一个文件,经过AI向量化之后存的向量数据就带有了更多的特征。这样,原本进行搜索时需要的精确匹配就可以很轻松的变成模糊匹配、甚至语义化的匹配。
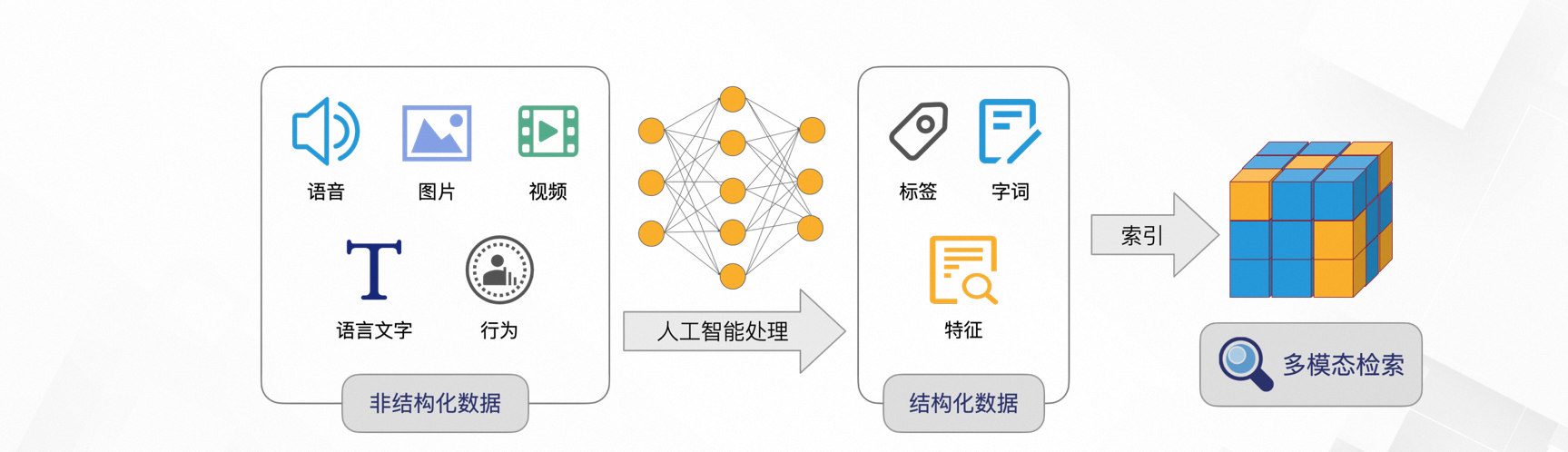
举个例子:
当我在微信的备注中给某个人添加了一段描述时,比如:“这是我老婆的哥哥的朋友,张三,他有显卡的一级代理,可以拿到很低的价格”。
正常来说,当我再想搜到这个人的时候,我需要用比较精确的关键词,比如:“显卡”、“代理”、“哥哥”等,但显然我很可能记不了这么清楚。
但如果这段文字被向量化处理之后再存储,我就可以通过语义化的表述来搜索,比如:“我老婆的哥哥有个朋友是显卡代理,他叫什么?”。
此时只需要把这个问题也进行向量化,就可以去和数据库中的向量进行匹配,最终根据获得数据的置信度排序后把记过再交给AI进行一次上下文联想,获得最终的答案。
而在上述过程中,文本的向量化、上下文联想问答这些都已经有成熟的API可以调用,前者需要考虑的是需要多少维度(可以理解为需要多少特征),后者就写好对应的prompt即可。
但向量的存储、搜索如何实现呢?
Qdrant的出现就是为了解决这个问题。
这一年多里,实际上已经涌现出很多的向量数据库,甚至一些老牌的数据库也已经通过插件的形式支持存储向量数据,但我之所以选择Qdrant的原因很简单,一是开源、二是对硬件要求低、三是文档很清晰。
这样我就可以在数据量不特别高的情况下,自己搭建一个向量数据库、服务接口来完成存储、搜索的环节,实际体验下来,确实很不错。
要知道阿里云和腾讯云基于开源的向量数据库提供的服务,动辄就要几千块每年了。

部署的过程很简单,官方有docker,我还是通过dockpoly进行部署和管理,过程不再赘述。
部署之后,需要开放端口、根据文档写增删改查即可,这部是cursor帮我完成的,简直不要太丝滑。
最终,我实现的功能会更复杂一些,但基本脱离不开向量搜索的范畴,甚至我突然发现,以前很难实现的模糊搜索这不就搞定了?虽然有AI的成本,但deepseek这种鲶鱼的搅动下,这两年tokens的价格越来越白菜化了。
所以如果你也有类似的搜索需求,不要迟疑,抓紧搞起来吧!

